개괄
항해에 들어간 후 첫 프로젝트를 진행하였다.
목표
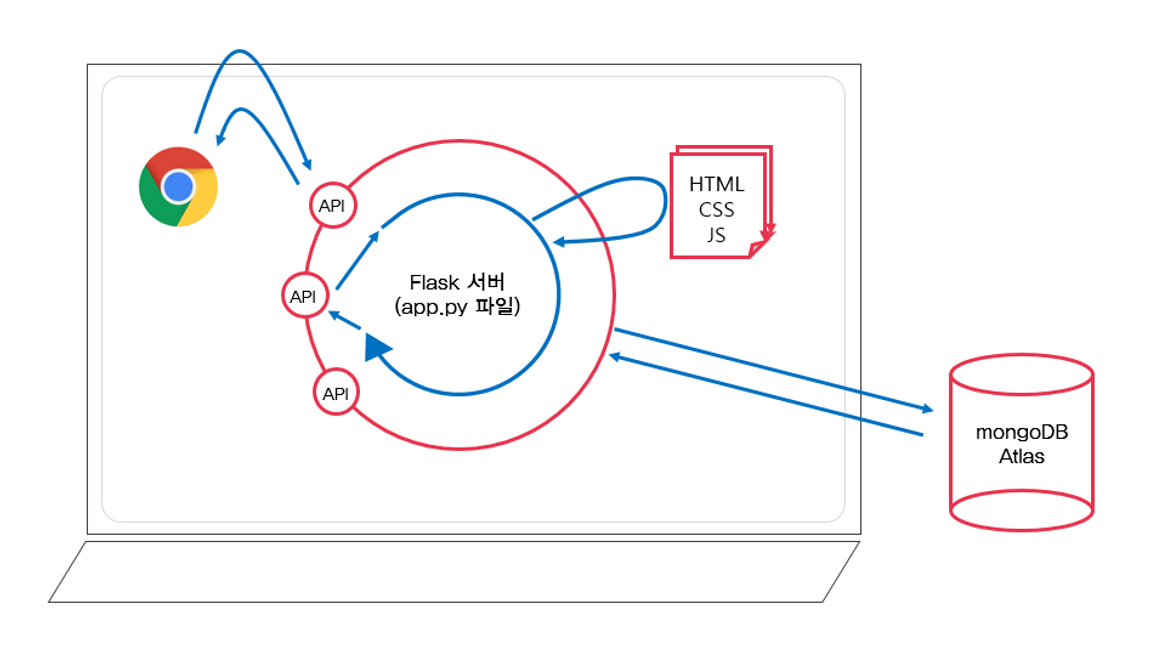
프로젝트는 flask와 html, css를 활용한 youtube player를 구현하기로 했고,
session을 이용한 로그인 화면 구현과 bs4를 이용한 유튜브 search result를 크롤링해서 플레이리스트에 추가, 삭제하기
등이 주요 과제가 되었다.
배운 것 - TIL SERIES (Link)
REST-API : 누구나 읽기 쉽게 설계하기
https://choincnp.tistory.com/21
TIL - REST API : 누구나 읽기 쉽게 설계하기
REST란? REpresentational State Transfer의 약자로, 자원(리소스)의 표현에 의한 상태 전달을 하는, HTTP를 잘 활용하기 위해 만든 ‘아키텍쳐’이다. 따라서 REST를 잘 지키지 않는다고 해서 ‘trash code’나
choincnp.tistory.com
협업 - 합리적인 소통하기
https://choincnp.tistory.com/18
웹 개발 프로젝트 목표 설정하기
첫 팀이 분배되고, 프론트 지향 2명과 백엔드 지향 2명이 같은 팀이 되었다. 문제점 프로젝트 주제에 대해서는 많은 아이디어가 나왔지만, 그 주제에 어떤 기능을 넣어야 할지, 모여서 무엇을 해
choincnp.tistory.com
git flow - trunk-based 기법을 활용한 팀원들의 소통
db 저장하기 - Mongo DB를 활용한 dictionary를 element로 가진 Array를 저장하기
0주차 Troubleshooting
목표 달성 여부
결과적으로 말하자면, 절반의 성공과 절반의 실패라고 볼 수 있다.
GIT REPOSITORY : https://github.com/choincnp/duoback_mini
<main page>

좌측 상단 : iframe을 이용한 현재 재생중인 유튜브 영상
좌측 하단 : mongoDB를 이용한 내가 선택한 playlist
우측 상단 : search tab을 활용한 유튜브 영상 검색
우측 하단 : search result
<login>

pymongo를 이용해 로그인 페이지와 회원가입 페이지를 만들고, ID와 PW는 몽고DB에서 관리, 로그인 정보는 session에서 관리하게 만들었다.
클라이언트단은 완벽하지만, 서버단의 구조는 매우 빈약한것을 볼 수 있다. 조금만 더 알았더라면, 조금만 더 공부했더라면 다른 팀원들이 구현하고자 했던 기능들을 더 구현할 수 있었는데, 내 능력의 부족으로 이루지 못해 너무 속상했고, 각오를 다졌다.
느낀 점
컴퓨터는 앞으로만 가지만, 사람은 양방향성을 띈다.
앞으로만 가는 컴퓨터의 활동을 제어하는것은 쉽지만, 때로는 전진하고, 때로는 후퇴하는 사람을 제어하는것은 훨씬 힘든 일이다. 첫 협업에서부터 삐끗했던 활동을 생각하며, 옛날에 떠올렸던 '이런 사람과도 협업을 못하는데, 내가 과연 smooth한 협업을 진행할 수 있을까?'라는 생각을 다시금 했다.
내 코드는 컴퓨터만 읽는 게 아니라, 사람도 읽는다.

컴퓨터가 읽기 좋은 코드로 개발하는것도 좋지만, 사람이 읽기 좋은 코드로 개발하는것도 꼭 필요한 프로세스다.
읽기 쉽게 코딩하지 않으면 남들이 보는 데 거부감이 든다.
제대로 알지 못하면, 안 하느니만 못하다.
인강을 다 들었어도 실제 구현을 하려고 하면 막막하기도 하고, 도대체 내가 무엇을 하고 있는지, 어디에 있는지조차 헷갈린다.
다음 주 목표
- 위의 것들을 기반으로 한 원활한 소통과 협업이 이루어지는, '케미스트리'가 가득한 오케스트라 같은 팀 구성하기.
- RESTful한 API 설계로 모르는 사람이 보아도 한 눈에 무슨 api인지 알게 하기
- code-convention과 commit-convention으로 명확한 의미를 지닌 코드/소통 설계하기
'웹개발 > 항해' 카테고리의 다른 글
| TIL - RestTemplate로 유튜브에서 검색결과를 받자 (0) | 2023.02.02 |
|---|---|
| 항해 2주차, 객체지향으로 가는 길 - Week I learned (0) | 2023.01.30 |
| 항해 웹개발 종합반 5주차, 서버 구동 (1) | 2023.01.07 |
| 항해 웹개발 종합반 4주차, 서버 연습(2) (0) | 2023.01.04 |
| 항해 웹개발 종합반 4주차, 서버 연습(1) (2) | 2023.01.04 |